Коротко
У обычного кода есть тесты. У AI-систем тоже должны быть тесты, просто они выглядят иначе. Модель может ответить разными словами, но бизнесу важно не совпадение текста, а поведение: нашла ли она правильный источник, не придумала ли факт, передала ли опасный кейс человеку.
Evals начинаются с ручного просмотра примеров. Возьмите реальные диалоги, ответы, документы, ошибки поддержки. Отметьте, где агент врёт, где теряет задачу, где отвечает слишком широко, где забывает эскалацию. Через 20-50 примеров обычно становится видно, какие 2-3 типа ошибок портят большую часть результата. Вот их уже можно автоматизировать.
После этого можно автоматизировать проверки. Часть ловится кодом: JSON валиден, ответ короче лимита, есть ссылка на источник, сработал отказ. Часть требует LLM-as-judge: другая модель оценивает, был ли ответ верным, полным, вежливым, безопасным. Такой судья тоже не святой, поэтому его надо калибровать на человеческих оценках.
Для RAG отдельно проверяют retrieval. Если система не нашла нужный фрагмент, бесполезно ругать финальный ответ. Если фрагмент найден, но модель всё равно добавила лишний факт, смотрим промпт, модель и инструкцию на отказ.
Evals полезны до запуска, потому что позволяют довести агента на наборе неприятных сценариев. После запуска они ещё важнее: реальные пользователи быстро приносят новые формулировки, новые ошибки и новые документы. Хороший eval-набор живёт вместе с продуктом.
Самая практичная польза простая. Команда перестаёт спорить “стало лучше или нет” и начинает видеть цифры: какие сценарии прошли, какие упали, где деградация, где можно перейти на более дешёвую модель. Это скучнее, чем магия промптов. Зато так AI становится управляемым.
Что такое eval на практике
Eval — это повторяемая проверка качества AI-системы.
Иногда это обычный assert: ответ должен быть валидным JSON, содержать ссылку на источник, быть короче 800 символов или вызвать нужный tool. Иногда это ручная оценка по рубрике. Иногда это LLM-as-judge: отдельная модель читает вход, найденный контекст и ответ, а потом ставит оценку.
Главное не инструмент. Главное, что один и тот же сценарий можно прогнать снова после изменения промпта, модели, retrieval, tools или релиза.
Поэтому evals отличаются от демо. Демо показывает, что агент один раз справился. Eval показывает, справляется ли он дальше, когда начинается нормальная инженерная жизнь: новые документы, новые формулировки пользователей, более дешёвая модель, сломанная интеграция и неприятные edge cases, которые никто не вставляет в красивую презентацию.
Почему тестирование “на ощущениях” ломается
Большинство AI-проектов сначала живёт в таком цикле:
- Кто-то поправил промпт.
- Прогнал пять примеров в чате.
- Два ответа стали лучше.
- Один ответ странный, но вроде терпимо.
- Команда выкатила изменение, потому что встреча заканчивается.
Это понятно. И именно так появляются регрессии.
AI-системы неудобны тем, что одно изменение может улучшить видимые примеры и сломать скрытый пласт поведения. Более строгий промпт уменьшил галлюцинации, но начал отказывать там, где надо отвечать. Более дешёвая модель хорошо прошла FAQ, но развалилась на многошаговых кейсах. Новый retriever стал лучше искать по смыслу, зато хуже находить точные ID.
Без evals эти компромиссы не видны. Разговор превращается во вкус: “этот ответ приятнее”, “раньше звучало теплее”, “новая модель вроде умнее”. Evals не отменяют человеческое суждение, но возвращают спор к фактам.

Начните с разбора ошибок, а не с огромного набора тестов
Первый eval-набор обычно должен быть небольшим и неприятным.
Возьмите 20-50 реальных или реалистичных примеров. Не выбирайте только удачные сценарии. Нужен тикет, где агент придумал регламент. Чат продаж, где он пообещал скидку. HR-вопрос, где важны права доступа. Поиск по документам, где ответ спрятан в таблице.
Для каждого примера запишите:
- вопрос пользователя;
- документы, CRM-записи или результаты tools, которые система должна использовать;
- ожидаемый ответ или ожидаемое действие;
- что делает ответ опасным или бесполезным;
- насколько серьёзна ошибка.
Потом пометьте типы ошибок простыми словами: не тот источник, факт без опоры, пропущена эскалация, неверный tool call, слишком длинно, нарушен доступ, не тот язык, сломался формат.
Через короткий разбор появляются паттерны. Агент нормально отвечает на FAQ, но ломается на исключениях по цене. RAG достаёт правильный документ, но модель игнорирует таблицу. Follow-up для продаж хороший, пока клиент не просит обещание, которое компания не готова дать.
Сначала стройте evals вокруг таких ошибок. Общие метрики пригодятся позже. Первая задача — ловить то, что реально вредит бизнесу.
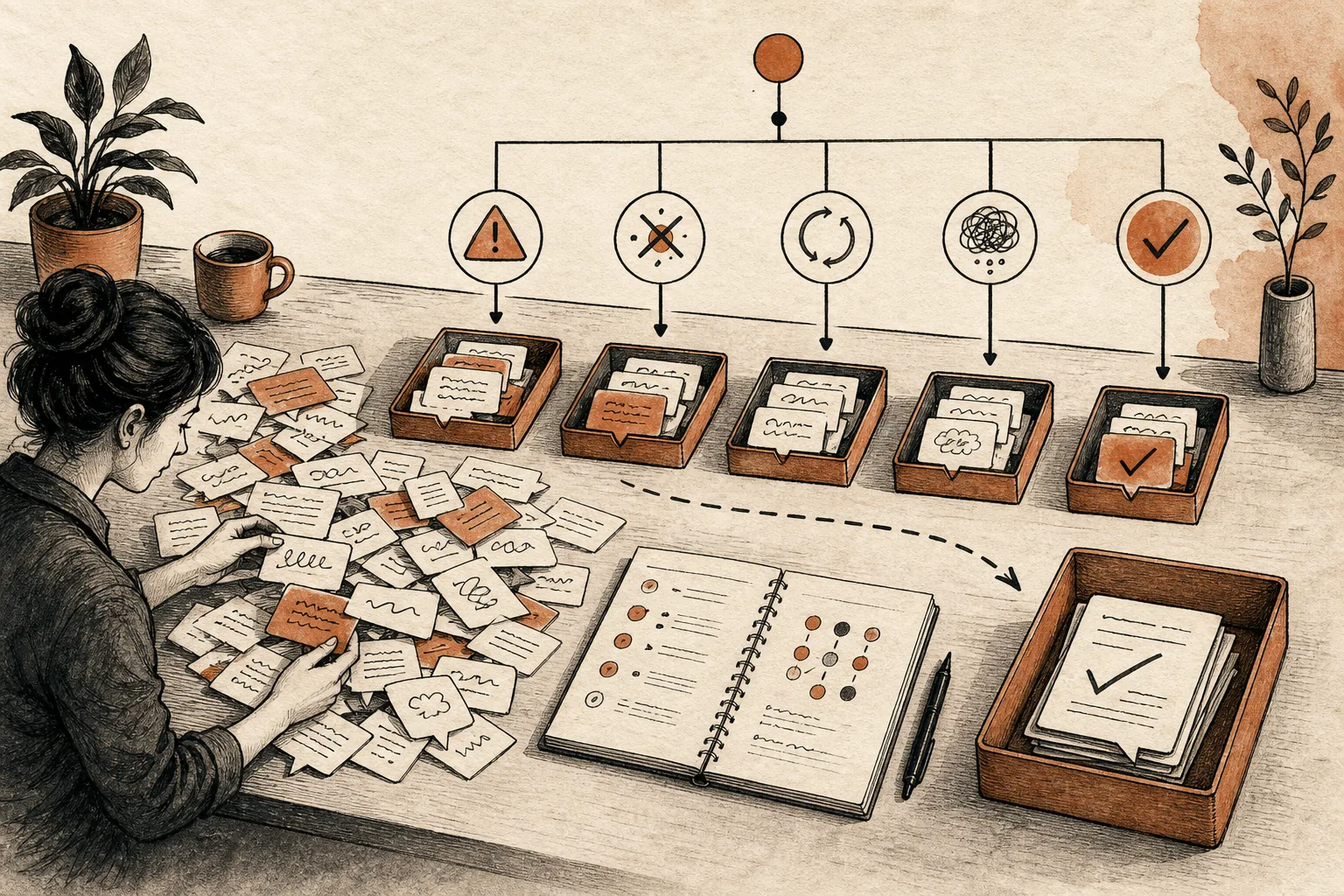
Три слоя evals
В production обычно нужны три слоя проверок.
Детерминированные проверки ловят то, что можно проверить кодом. Ответ совпадает со схемой? Агент вызвал create_crm_task только после того, как нашёл ID клиента? В ответе есть источник? Запрещённый запрос отклонён? Ответ укладывается в лимит символов?
Такие проверки дешёвые, быстрые и полезно скучные. Их стоит использовать везде, где можно.
Ручная оценка нужна там, где есть смысл и контекст. Человек видит, пропущено ли главное решение в резюме встречи, звучит ли ответ продажника слишком напористо, запутает ли инструкция сотрудника. На ручных оценках ещё и калибруют LLM-as-judge.
LLM-as-judge помогает масштабировать смысловую проверку. Модель-судья может оценивать faithfulness, полноту, релевантность, тон, следование инструкции. Это практично, но не волшебно. Судье нужны понятная рубрика, пороги, примеры и регулярное сравнение с человеческими оценками.
Фреймворки вроде DeepEval удобны, потому что дают знакомую форму: datasets, test cases, metrics, thresholds, повторные прогоны. Но фреймворк — это обвязка. Метрику выбирает бизнес-задача, а не меню в библиотеке.
DeepEval, Ragas, OpenAI Evals, promptfoo, Braintrust, LangSmith и Phoenix решают разные части одной задачи. Одни удобнее как локальный test runner. Другие сильнее в traces, datasets, experiments или production monitoring. Не начинайте с логотипа. Начинайте с ошибки, которую надо поймать.

Что проверять в RAG
RAG нужно проверять отдельно, потому что “ответ неправильный” может означать разные поломки.
Если retrieval не нашёл нужный источник, модель может быть ни при чём. Она отвечала из неправильного контекста, потому что система дала ей неправильный контекст. Если retrieval нашёл нужный фрагмент, а модель всё равно добавила лишний факт, тогда подозреваем промпт, модель, формат контекста или правило отказа.
Подробнее про устройство retrieval есть в статье Как построить хороший RAG. Для evals короткий список такой:
- Retrieval recall: нашла ли система источник, где есть ответ.
- Retrieval precision: не притащила ли она слишком много мусора.
- Source coverage: хватает ли контекста для ответа или надо честно сказать “не знаю”.
- Faithfulness: остался ли финальный ответ внутри найденных источников.
- Citation quality: правда ли ссылки и фрагменты подтверждают тезисы.
- Access control: использовал ли ответ только те документы, которые пользователь имеет право видеть.
Для внутреннего ChatGPT компании это особенно важно. Сотрудники спрашивают грязно и по-человечески: “что делать с этим клиентом?”, “можно ли списать этот расход?”, “где последняя версия шаблона?” Уверенного тона мало. Ассистент должен найти правильный источник, уважать роли доступа и признать, когда в базе знаний нет ответа.
Что проверять у агентов и tools
У агентов появляется ещё одна зона риска: действия.
Чат-бот может ошибиться текстом. Агент может ошибиться в CRM, календаре, тикет-системе, базе данных или черновике письма. Поэтому eval-набор меняется.
Для агента проверяют:
- выбрал ли он правильный tool;
- передал ли правильные аргументы;
- проверил ли результат tool перед следующим шагом;
- остановился ли, когда данных не хватает;
- попросил ли подтверждение перед рискованным действием;
- оставил ли понятный лог для человека.
Например, в ИИ для отдела продаж eval должен проверять больше, чем красоту follow-up письма. Важно, зафиксировал ли агент следующий шаг, не пообещал ли запрещённые условия, обновил ли правильную сделку в CRM и передал ли исключение по цене руководителю.
Хорошие evals позволяют выдавать автономность постепенно. Сначала агент только пишет черновик. Потом создаёт задачи. Потом отправляет низкорисковые сообщения. На каждом шаге есть доказательство, что это не просто смелость.
Первый eval-набор на месяц
Чтобы начать, не нужна исследовательская лаборатория.
Для первого production AI-проекта я бы собрал так:
- 30-50 базовых примеров из реальной работы;
- 10-20 неприятных edge cases от команды;
- несколько примеров, где система обязана отказать;
- несколько длинных контекстов;
- несколько двуязычных примеров, если продукт работает на двух языках;
- holdout-набор, который не используют во время настройки промпта.
У каждого примера должен быть владелец со стороны бизнеса. Кто-то должен уметь сказать: это достаточно хорошо, это опасно, это просто некрасиво.
Видимый набор гоняют во время разработки. Holdout лучше держать для релизной проверки, чтобы команда случайно не подогнала промпт под примеры, которые все уже выучили.
Если в production случилась серьёзная ошибка, добавьте её в suite. Так evals становятся рабочим инструментом, а не ритуалом. Каждая болезненная ошибка покупает будущий regression test.

Как evals влияют на стоимость
Evals помогают с качеством, но на этом польза не заканчивается. Они ещё и про деньги.
Самая дорогая модель не всегда нужна везде. Когда команда может прогнать одни и те же сценарии на разных моделях, появляется нормальное сравнение: качество, скорость, цена. Возможно, обычные FAQ проходят на модели дешевле. Вопросы по документам и юридическим формулировкам требуют сильной модели. Планирование действий можно оставить дорогой модели, а финальное форматирование отдать простой.
Поэтому evals должны быть в разговоре о бюджете. В статье Сколько стоит внедрение ИИ в Казахстане та же мысль раскрыта с другой стороны: production AI не сводится к оплате model calls. Деньги уходят на то, чтобы система была измеримой, поддерживаемой и достаточно безопасной для реальных пользователей.
Без evals смена модели — догадка. С evals это инженерное решение.

Как встроить evals в процесс
Здоровый цикл выглядит так:
- Собрать примеры из реального использования или реалистичных сценариев.
- Разобрать их вручную и назвать типы ошибок.
- Перевести важные ошибки в deterministic checks, ручные рубрики или LLM-judge метрики.
- Запускать suite перед изменениями промпта, модели, retrieval или tools.
- Держать holdout-набор для релизной уверенности.
- Добавлять production bugs обратно в suite.
Быстрые проверки можно запускать в CI на каждое изменение. Более медленные LLM-judge прогоны — перед релизом или по расписанию. Ручной review лучше тратить на новые типы ошибок, а не на бесконечное перечитывание очевидных кейсов.
Цель не в том, чтобы сделать AI полностью предсказуемым. Не получится. Цель в том, чтобы безопаснее менять систему. Нужно видеть, куда двинулось качество, на каких сценариях и почему это важно.